/
API Caller Functional Overview
API Caller Functional Overview
- Gidi Shalev (Unlicensed)
Owned by Gidi Shalev (Unlicensed)
Jan 13, 2020
What is the API Caller?
The API Caller enables calling RESTful APIs from legacy applications.Overview:
There are separate Design-time and Run-time phases.
In the Design-time phase:
The user imports an API specification and edits it
The system generates Endpoint definition metadata from the Swagger Specification
The user can edit the Endpoint definition metadata
The user downloads standard legacy files (e.g., Cobol Copybooks files) generated from the Endpoint definition metadata
In the Run-time phase
The legacy program can call the API using the generated Cobol Copybooks code (previously described in the Design-time phase)
The code uses the API Caller as a proxy for RESTful Requests/Responses
The legacy program transfers the buffer to the API Caller that converts it to a REST request to the API and receives the response
The API Caller converts the response back to the buffer and transfers it back to the legacy program.
The system is secured and requires authentication.
Users are managed in the application's internal user base.
*Please note that we use the term 'Endpoint' to describe the API Specification definition metadata generated from the API Specification and managed in the API Caller application
Design
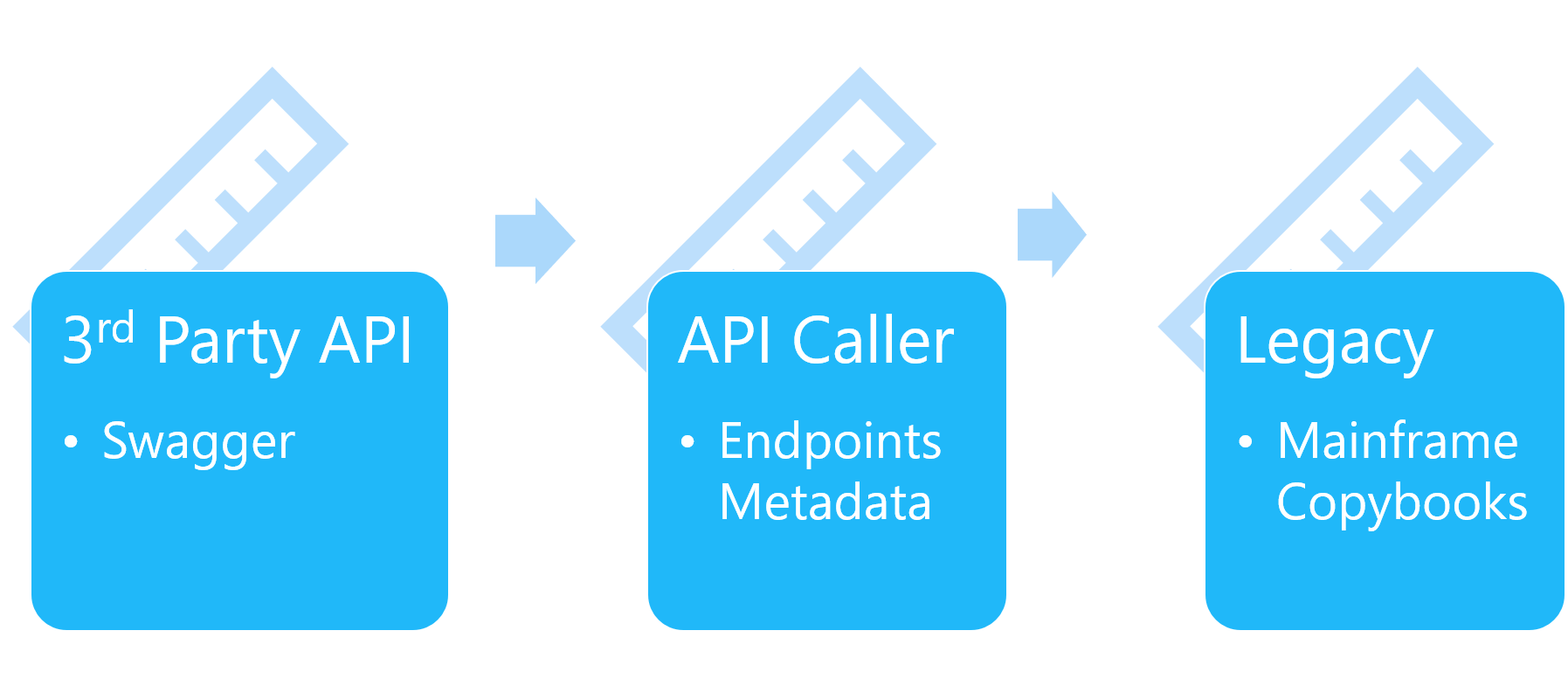
Runtime
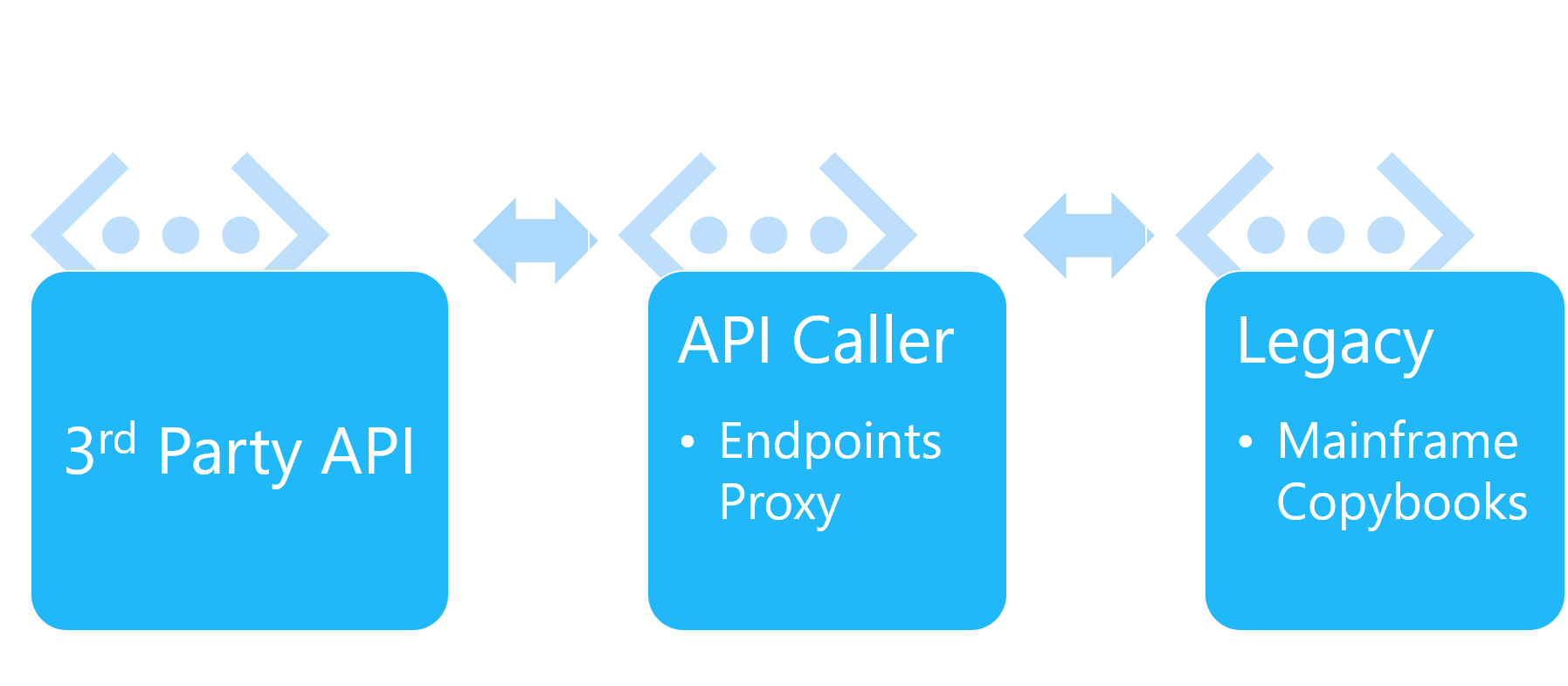
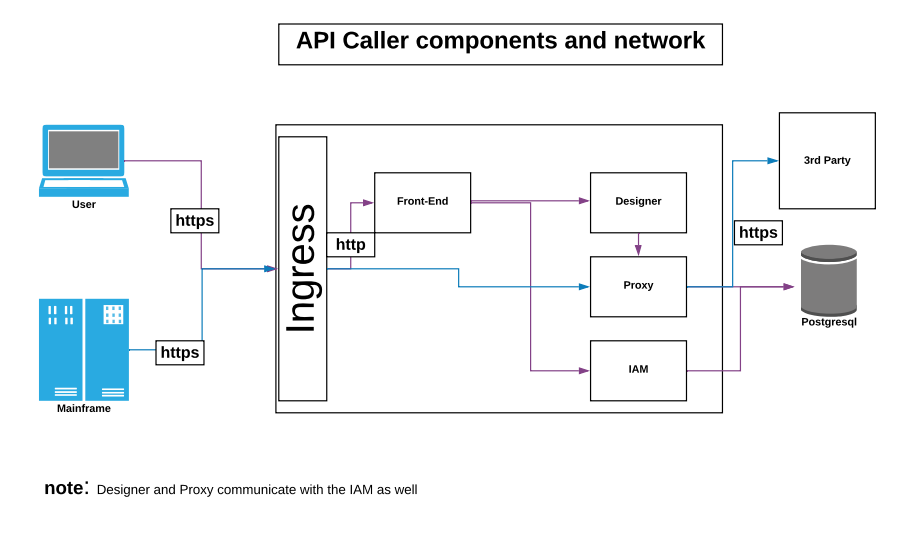
Technical Overview
Design-time Flow
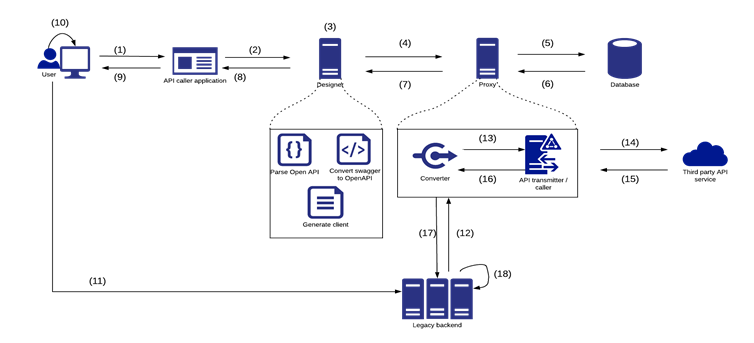
A user navigates to the API Caller application to perform actions on Endpoints/Design APIs using a specification editor
User’s request is sent to the designer component
If the action does not involve the use of a database – the request is handled by the designer itself.
If the action does involve the use of the database – the designer sent the request to the proxy component for further care
The proxy retrieves/updates the database according to the user’s requested action
The proxy receives ack/failure from the database based if the action succeeded or not
The proxy sends back the response to the designer component
The designer sends back the response to the application
The response is displayed to the user and s/he continues his work.
The user decides to generate client from the selected endpoints
The user deploys the proxy client to the legacy backend
The legacy backend sends a buffer request, based on the deployment proxy client, to the converter component to invoke the API service
The converter converts the buffer to an HTTP Request model and sends it to the transmitter/ caller.
The transmitter/ caller sends the HTTP request to invoke the API service.
The API service sends back the HTTP response to the transmitter/ caller.
The transmitter/ caller sends back the HTTP response to the converter.
The converter converts the HTTP response to a buffer and sends it back to the legacy backend.
The legacy backend processes the response and continues its work.
Run-time (Proxy) Flow
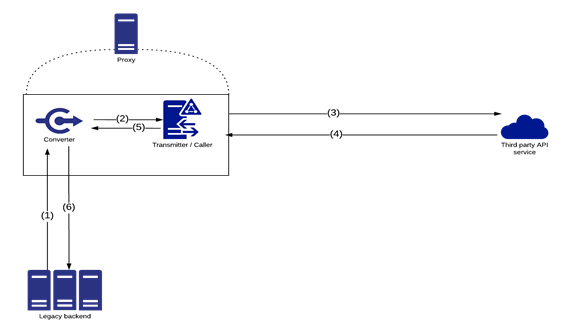
Program on the legacy backend initiates a request to the API Caller Proxy using the data of a provided proxy client in the request
The Converter receives the buffer from the legacy backend and converts it to an HTTP request and sends it to the Transmitter/Caller
The Transmitter/Caller sends the HTTP request to the 3rd-party API service.
The API responds with an HTTP response
The Transmitter/Caller navigates the response back to the Converter.
The Converter converts the response back to a buffer that fits the client proxy on the legacy backend side and sends it back to the legacy backend
Functional Limitations
API Caller API Authentication
Currently, only Basic authentication is supported
API Caller OpenAPI Swagger Parser
The API Caller Swagger parser supports the following utilities and features:
- We use OpenAPIParser.readContent to parse Swagger V3 specification files
- We use SwaggerConvertor to read the contents of Swagger V2 and convert it to V3.
- Both libraries are of Swagger V3
- For the V3 specification file, we use the parse-options of “isResolve” (unites all specification file references in the “component” section. The “component” section is part of the OpenAPI model).
- For the V2 specification file, we use the “isResolveFully” parse-options to change the ref name from the “definition” section to the “component” section (the “definition” section has the same purpose as the “components” section, but is used only for V2)
- readLocation supports relative references (references that point to files in the same path) but does not pass Gradle clean builds on larger specification files. We use the “readContent” function instead, but this function cannot read relative references.
- We support parsing of YAML and JSON files
- We support parsing V2 and V3 specification files. Note that V1 is unsupported
- Each specification file has a “Servers” section which specifies the API server and base URL. Although you can define several servers, we currently support only one. We initially search for servers that begin with the HTTPS protocol, but if not found we will select a server that begins with the HTTP protocol to be our base URL.
- The global “components” section defines common data structures used in a given API.
They can be referenced via $ref in the parameters/ request body and responses. We support all of them. - We currently do not support the relative ref and remote ref References
- Basic Authentication is supported
- We support the case of overriding base path URLs, if there are several operations in different paths/ or in the same path that use their own servers’ section. This is useful if some endpoints use a different server or base path than the rest of the API. As mentioned in paragraph 8 we first check to find a URL that uses HTTPS schema, else we provide a server that uses the HTTP schema as default
- If there is no base path at all, we just provide “/” character as the base path
- We currently only support the application/JSON media type for both consuming and producing. If there is no JSON media type in the given specification file, we do not insert the specific operation (the operation that uses the unsupported media type) to the map of HttpEndpoints and we log the appropriate message. If no media type is provided at all in the spec, we use the JSON media type to consume and produce as default.
- We support all parameters types (body, header, cookie, path, query)
Cookie and header parameters are converted to the string data type. - The cookie appears as part of the headers list in our HttpEndpoint model.
- We support the “required” keyword to mark a parameter as required (path param will always be marked as required even though the keyword is not always provided in the spec).
- We support the default serialization method for array and object parameters (style and explode keywords):
- For path param- style: simple, explode false
- For query param- style: form, explode true
- For header param- style: simple, explode false
- For cookie param- style: form, explode true
- Any other serialization that does not appear in the list above is not supported. In addition, the entire operation that contains the parameters with this specific serialization type is not inserted to the map of HttpEndpoints.
- We support default parameter values (if provided)
- We do not support keywords that are used for the level of the parameter: “nullable”, “allowEmptyValue” and “deprecated”
- Parameters that are declared on the path level instead of the operation level are also not supported
- OpenAPI 3.0 provides several keywords which you can use to combine schemas:
- oneOf – validates the value against exactly one of the sub-schemas.
- allOf – validates the value against all the sub-schemas.
- anyOf – validates the value against one or more of the sub-schemas.
- As a continuation to the previous paragraph - in the current version we relate to all keywords as “allOf” and provide a message that the user needs to handle the models accordingly as specified in the API.
- In the responses section, each response starts with an HTTP status code. If it starts with a number (e.g. 200) we save it as is. If it uses the saved word “default” – we store it as ” -1”. If it contains a general status code,e.g. 5XX, we save it as 500
- Responses headers are saved as strings
- String, number, integer, boolean, enum, object, and array data types are supported, but parameters defined as “mixed types” are unsupported.
- Minimum and maximum keywords are supported.
- “MultipleOf” keyword (specifies that a number must be a multiple of another number) is not supported
- String supported format = [date, date-time] and string unsupported format = [password, byte, binary, email, UUID, URI, hostname, ipv4, ipv6]
- “Pattern” keyword for strings is also not supported
- In Arrays data types- uniqueitems (keyword which specifies that all items in the array must be unique) is not supported
- The "Required" keyword can be represented as a list of required parameter names [“name”, “id”] or as Boolean [“true”, “false”]. We support both options
- ReadOnly properties are included in the responses but we do not have a special treatment for them (if the parameter in the request marked as readOnly, it means it returns by GET but not used in POST/PUT/PATCH)
- The same applies to WriteOnly properties (that appear on the requests). If the parameter in the request is marked as writeOnly, it means it used in POST, PUT,PATCH but not returned by GET. We don’t give it any special treatment either
- Nested objects are supported (parameter of type object inside of parameter of type object and so on)
- AnyValue - A schema without a type that matches any data type is not supported
- Examples/ Callbacks/ Links/ Authentication and Tags sections are out of the scope for the current version
, multiple selections available,
Related content
API Caller
API Caller
Read with this
Using API Caller
Using API Caller
More like this
API Caller - Release Notes
API Caller - Release Notes
Read with this
API Caller Error Handling
API Caller Error Handling
Read with this
API Caller の使い方
API Caller の使い方
More like this
API Architecture
API Architecture
More like this